

|
Ouverture de session
Navigation
Contactez-nous
Administration du site :
"equipe chez postgresqlfr point org"
Contact presse :
"fr chez postgresql point org"
Contact association :
"bureau chez postgresqlfr point org"
Questions PostgreSQL :
IRC :
serveur irc.freenode.net
canal #postgresqlfr
Recherche
Sujets du forum
Sujets actifs
Nouveaux sujets:
Syndication
Sondage
Index inversûˋ, en C
| Index inversûˋ, en C
Par Guillaume Lelarge le 05/09/2007 - 18:33
Depuis la version 8i, Oracle implûˋmente les index inversûˋs. Voici une proposition dãimplûˋmentation ûˋquivalente pour PostgreSQL. Les index inversûˋs permettent dãaccûˋlûˋrer les recherches sur les motifs tels que ô¨ colonne LIKE '%chaûÛne' ô£. Dans un tel cas, PostgreSQL effectue un parcours sûˋquentiel (ou ô¨ sequential scan ô£) de la table interrogûˋe. Toutefois, il est possible dãûˋmuler un index inverse au moyen dãune fonction de renversement de chaûÛne couplûˋe û un index sur fonction.
L'article prûˋcûˋdent proposait l'implûˋmentation d'un prototype en langage procûˋdural PL/pgSQL, qui fait office ici de prototype. Cette implûˋmentation a pour principal dûˋfaut d'ûˆtre lente, pûˋnalisant ainsi gravement les performances en ûˋcriture (INSERT et UPDATE). Ainsi, û chaque mise û jour, il est nûˋcessaire de faire appel û la fonction reverse pour mettre û jour l'index fonctionnel ; cela s'observe notamment û la crûˋation de l'index. En revanche, il est possible de tirer partie des capacitûˋs de traitement des caractû´res multi-octets, que l'on rencontre notamment dans le cas d'une base de donnûˋes encodûˋe en UTF-8.
Ainsi, l'implûˋmentation en langage C se doit d'ûˆtre û la fois plus rapide et surtout se doit de supporter les jeux de caractû´res multi-octets. C'est û partir de ce minuscule cahier des charges que nous allons construire notre fonction reverse.
Pourquoi ûˋcrire une procûˋdure stockûˋe en C
Pourquoi s'embûˆter û prendre le temps d'ûˋcrire une procûˋdure stockûˋe en langage C alors qu'il est possible de faire la mûˆme chose en langage PL/pgSQL ?
Il y a plusieurs rûˋponses û cette question :
- Une fonction C permet de protûˋger le code. En effet, rien n'interdit û un utilisateur possûˋdant les droits nûˋcessaires de modifier la procûˋdure stockûˋe que l'on a ûˋcrite et validûˋ par une autre procûˋdure de son crue, rendant le systû´me inopûˋrant.
- Si le besoin de crûˋer son propre type de donnûˋes se fait sentir, le passage par la case
fonction C
est obligatoire. - La satisfaction de connaûÛtre un peu mieux le fonctionnement interne de PostgreSQL, mais c'est surtout une satisfaction de geek :)
- La problûˋmatique de la vitesse est toutefois le facteur dûˋterminant de la rûˋûˋcriture d'une fonction d'un langage procûˋdural interprûˋtûˋ en langage compilûˋ.
Le gain significatif de vitesse ne sera pas ûˋvident pour les requûˆtes de sûˋlection. En revanche, les ûˋcritures (surtout INSERT et UPDATE) peuvent ûˆtre fortement pûˋnalisûˋes par le coû£t de la mise û jour d'un index fonctionnel. Bien que cela ne soit pas ûˋvident pour une opûˋration unitaire, il sera parfaitement visible dans le cas d'une opûˋration d'ûˋcriture en masse (chargement massif de donnûˋes), ou tout simplement pour la crûˋation de l'index fonctionnel. Dans un tel cas, l'option d'une rûˋûˋcriture en langage C est û envisager trû´s sûˋrieusement.
Implûˋmentation et discussion technique
Les possibilitûˋs d'extension de PostgreSQL sãappuient sur les mûˋcanismes de chargement dynamique de bibliothû´que du systû´me dãexploitation. Lãinterface de programmation est relativement simple, û condition dãen connaûÛtre certaines clûˋs.
Structure du projet
Le projet est articulûˋ autour de diffûˋrents fichiers, qui seront tous placûˋs dans un rûˋpertoire dûˋdiûˋ :
- un fichier
Makefilesimplifiûˋ, utilisant PGXS, l'infrastructure de construction d'extension PostgreSQL ; - un modû´le de script SQL d'installation
reverse.sql.in; - un fichier
uninstall_reverse.sql; - le fichier source en langage C,
reverse.c.
Fichiers annexes
Avant toute chose, il faut disposer dãun fichier ô¨ Makefile ô£ de construction du module externe :
MODULES = reverse
#PG_CPPFLAGS = -ggdb
DATA_built = reverse.sql
DATA = uninstall_reverse.sql
PGXS := $(shell pg_config --pgxs)
include $(PGXS)
Le Makefile utilise ici lãoutil PGXS qui propose un fichier Makefile prûˋdûˋfini, û lãinstar des fichiers Makefile fournis par Oracle.
Le fichier ô¨ reverse.sql.in ô£ qui sert de modû´le û la crûˋation du fichier d'installation de l'extension ô¨ reverse.sql ô£. Ce dernier fichier sera gûˋnûˋrûˋ û partir du modû´le en remplaûÏant ô¨ MODULE_PATHNAME ô£ par le chemin complet du fichier objet gûˋnûˋrûˋ.
-- Dûˋclaration de la fonction reverse en tant que module C
SET search_path = public;
CREATE OR REPLACE FUNCTION reverse(varchar) RETURNS varchar
AS 'MODULE_PATHNAME', 'reverse'
LANGUAGE 'C' IMMUTABLE STRICT;
Le script ô¨ reverse.sql ô£ sera exûˋcutûˋ par un utilisateur PostgreSQL ayant le rûÇle dãadministrateur, les fonctions C ûˋtant considûˋrûˋes comme non-sû£res et donc de la responsabilitûˋ de lãadministrateur.
Un script de dûˋsinstallation ô¨ uninstall_reverse.sql ô£ est ûˋgalement prûˋvu, ûÏa fait toujours plaisir :
SET search_path = public;
DROP FUNCTION reverse(varchar);
Un peu de technique
La lecture de la page ô¨ Fonctions en langage C ô£ permet dãobtenir les informations nûˋcessaires au dûˋveloppement dãune fonction C, voir la documentation ô¨ Fonctions en langage C ô£. Cependant la lecture des fichiers dãen-tûˆtes permet dãapporter un ûˋclairage supplûˋmentaire sur certaines structures de donnûˋes.
Traitement des chaûÛnes de caractû´res avec PostgreSQL
Sous PostgreSQL, les chaûÛnes de caractû´res ne sont pas dûˋlimitûˋes par un caractû´re nul ô¨ \0 ô£ terminal, mais, û lãinstar du langage Pascal, en stockant dans une structure dãabord sa longueur puis son contenu. Une telle chaûÛne est dûˋcrite dans une structure de type ô¨ varlena ô£. Ce type de donnûˋes offre en fait un moyen uniforme de stocker tout type de donnûˋes û longueur variable, comme les chaûÛnes de caractû´res, les tableaux ou encore les types utilisateurs.
Voici sa dûˋfinition, obtenu dans le fichier d'en-tûˆte c.h, û la ligne 409 :
struct varlena
{
int32 vl_len_; /* Do not touch this field directly! */
char vl_dat[1];
};
Ainsi, l'entier vl_len contient la longueur, en octets, de la chaûÛne d'octets vl_dat.
Quelques macros permettent de manipuler facilement cette structure.
VARDATA(varlena)obtient un pointeur sur la donnûˋe ;VARSIZE(varlena)obtient la taille en octets de la structure varlena (vl_len + vl_dat) ;- la constante
VARHDRSZreprûˋsente la taille en octet devl_len; - Enfin,
VARATT_SIZEP, remplacûˋe parSET_VARSIZEû partir de la 8.3, permet de dûˋfinir la longueur en octets de la donnûˋe.
Ainsi, pour obtenir la longueur en octets de la donnûˋes, on utilisera (VARSIZE - VARHDRSZ).
Support des jeux de caractû´res multi-octets
L'implûˋmentation proposûˋe supporte les jeux de caractû´res multi-octets, comme l'UTF8 (ou Unicode) et les jeux de caractû´res asiatiques, qui reprûˋsente certains caractû´res sous la forme d'une sûˋquence de deux octets ou plus (voir rûˋfûˋrence). PostgreSQL met û disposition des fonctions utiles pour manipuler les chaûÛnes de caractû´res, peu importe l'encodage, notamment pg_verifymbstr qui valide une chaûÛne de caractû´re selon l'encodage de la base de donnûˋes, ou encore pg_mblen qui donne la longueur en octets d'un caractû´re. Pour le prototype des fonctions citûˋes et d'autres fonctions, se rûˋfûˋrer au fichier d'en-tûˆte ô¨ mb/pg_wchar.h ô£.
Les conventions d'appel
Il existe deux conventions d'appel de fonctions externes :
- La convention d'appel version 0, reprûˋsentant l'ancien style, simple û utiliser ;
- La convention d'appel version 1, qui est la norme dorûˋnavant et qui ne prûˋsente pas de difficultûˋs particuliû´res.
La convention d'appel version 1 sera utilisûˋe dans le but de donner d'entrûˋe de jeu de bonnes habitudes. La complexitûˋ de cette convention est masquûˋe par une batterie de macros qui rendent son utilisation tout aussi simple, voire encore plus simple que la version 0, notamment pour le passage d'arguments.
Implûˋmentation en langage C
Le source C est structurûˋ en quatre parties :
- Lãinclusion des fichiers dãen-tûˆtes nûˋcessaires ;
- La dûˋfinition dãun ô¨ magic ô£ signant un module externe PostgreSQL ;
- La dûˋfinition dãun ô¨ magic ô£ dûˋclarant la fonction reverse û PostgreSQL ;
- Le corps de fonction reverse, cette fois en langage C.
Voici ci-aprû´s, le code source en langage C de la fonction reverse.
/*
* reverse procedural function
*
* Thomas Reiss, 12/07/2007 ã 24/07/2007 - 02/08/2007
* Alain Delorme, 24/07/2007
* Merci û depesz pour ses tests sur la version 8.3devel
*
*/
#include "pg_config.h"
#include "postgres.h"
#include "fmgr.h"
#include "mb/pg_wchar.h"
#include "utils/elog.h"
#ifdef PG_MODULE_MAGIC
PG_MODULE_MAGIC;
#endif
Datum
reverse(PG_FUNCTION_ARGS);
// SET_VARSIZE correspond û la nouvelle API, nous dûˋfinissons cette
// macro pour les versions ne la possûˋdant pas.
#ifndef SET_VARSIZE
#define SET_VARSIZE(n,s) VARATT_SIZEP(n) = s;
#endif
/* fonction reverse */
PG_FUNCTION_INFO_V1(reverse);
Datum
reverse(PG_FUNCTION_ARGS)
{
int len, pos = 0;
VarChar *str_out, *str_in;
/* Obtient l'adresse de l'argument */
str_in = PG_GETARG_VARCHAR_P_COPY(0);
/* Calcul de la taille en octet de la chaûÛne */
len = (int) (VARSIZE(str_in) - VARHDRSZ);
/* Crûˋer une chaûÛne vide de taille identique */
str_out = (VarChar *)palloc(VARSIZE(str_in));
/* La structure rûˋsultante aura une longueur identique */
SET_VARSIZE(str_out, VARSIZE(str_in));
/* Vûˋrifie que l'encodage de la chaûÛne en argument
* concorde avec l'encodage de la BDD */
pg_verifymbstr(VARDATA(str_in), len, false);
/* Copie û l'envers de la chaûÛne */
while (pos < len)
{
int charlen = pg_mblen(VARDATA(str_in) + pos);
int i = charlen;
// Copie un caractû´re.
// !! Un caractû´re != un octet
while (i--)
*(VARDATA(str_out) + len - charlen + i - pos) = *(VARDATA(str_in) + i + pos);
pos = pos + charlen; // incrûˋmente le compteur
}
PG_FREE_IF_COPY(str_in, 0);
/* Retourne la copie */
PG_RETURN_VARCHAR_P(str_out);
}
Construction
La construction de l'extension PostgreSQL est rûˋalisûˋe en invoquant make
tom@clementina:~/src/reverse$ make
cc -g -Wall -O2 -fPIC -Wall -Wmissing-prototypes -Wpointer-arith -Winline -Wdeclaration-after-statement -Wendif-labels -fno-strict-aliasing -g -fpic -I. -I/usr/include/postgresql/8.2/server -I/usr/include/postgresql/internal -D_GNU_SOURCE -I/usr/include/tcl8.4 -c -o reverse.o reverse.c
cc -shared -o reverse.so reverse.o
rm reverse.o
Si tout s'est bien passûˋ, l'installation sera finalisûˋe en exûˋcutant la commande make install, ûˋventuellement prûˋcûˋdûˋ de sudo en fonction de sa distribution et de son installation de PostgreSQL.
tom@clementina:~/src/reverse$ sudo make install
Password: xxxx
/bin/sh /usr/lib/postgresql/8.2/lib/pgxs/src/makefiles/../../config/install-sh -c -m 644 ./reverse.sql '/usr/share/postgresql/8.2/contrib'
/bin/sh /usr/lib/postgresql/8.2/lib/pgxs/src/makefiles/../../config/install-sh -c -m 755 reverse.so '/usr/lib/postgresql/8.2/lib'
Les fichiers produits seront ainsi installûˋs dans le rûˋpertoire d'installation de PostgreSQL. Il est toutefois possible de les positionner ailleurs, û condition d'adapter le fichier ô¨ reverse.sql ô£ de faûÏon û indiquer û PostgreSQL
oû¿ se trouve la bibliothû´que partagûˋe (fichier ô¨ reverse.so ô£ sous Linux).
Utilisation et performances
Vûˋrification de bon fonctionnement
Dans un premier temps, on crûˋe la fonction via l'outil psql :
test=# \i reverse.sql
CREATE FUNCTION
On vûˋrifie que la fonction rûˋpond correctement :
test=# SHOW client_encoding;
client_encoding
-----------------
UTF8
(1 ligne)
test=# SELECT reverse('ChaûÛne û renverser');
reverse
--------------------
resrevner û enûÛahC
(1 ligne)
Ok, ûÏa marche, y compris avec les chaûÛnes encodûˋes en UTF-8 !
Petit test de performance
Ce test a ûˋtûˋ rûˋalisûˋ par depesz, qui m'a aimablement autorisûˋ a le rûˋutiliser dans le cadre de cet article.
Petit aperûÏu du jeu de test :
test=# SELECT count(*),
test-# min(length(filepath)),
test-# max(length(filepath)),
test-# sum(length(filepath))
test-# FROM test;
count | min | max | sum
-------+-----+-----+----------
320136 | 7 | 174 | 18563865
(1 row)
Maintenant, voici une petite comparaison des trois implûˋmentations, û savoir le prototype en PL/pgSQL, la version PL/perl de depesz et la version C. On oppose û ces trois tests un parcours de la table via la fonction d'agrûˋgat count(), permettant ainsi de mesurer l'overhead due û chaque implûˋmentation de la fonction reverse. û chaque fois, 3 exûˋcutions permettent de vûˋrifier les rûˋsultats.
Simple comptage (count)
Voici l'ordre SQL utilisûˋ pour rûˋaliser ce test :
test=# EXPLAIN ANALYZE
test-# SELECT count(filepath)
test-# FROM test;
Et voici les temps de rûˋponse obtenus :
Exûˋcution #1 : 1269.535 ms
Exûˋcution #2 : 1268.421 ms
Exûˋcution #3 : 1257.926 ms
Moyenne : 1265,29 ms
Prototype PL/pgSQL
test=# EXPLAIN ANALYZE
test-# SELECT count(reverse_plpgsql(filepath))
test-# FROM test;
Exûˋcution #1 : 55269.941 ms
Exûˋcution #2 : 56047.004 ms
Exûˋcution #3 : 56149.888 ms
Moyenne : 55822,28 ms
Version PL/perl
test=# EXPLAIN ANALYZE
test-# SELECT count(text_reverse(filepath))
test-# FROM test;
Exûˋcution #1 : 4088.625 ms
Exûˋcution #2 : 4089.729 ms
Exûˋcution #3 : 4020.500 ms
Moyenne : 4066,28 ms
Version C
test=# EXPLAIN ANALYZE
test-# SELECT count(reverse(filepath))
test-# FROM test;
Exûˋcution #1 : 1596.176 ms
Exûˋcution #2 : 1647.046 ms
Exûˋcution #3 : 1657.531 ms
Moyenne : 1633,58 ms
Synthû´se du test de performance
Voici un graphe faisant la synthû´se des moyennes des temps de rûˋponse :
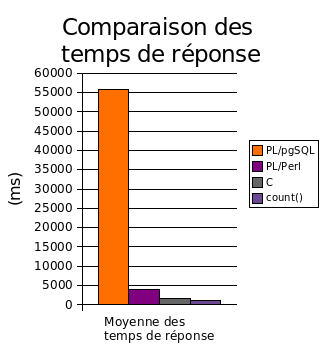
Le graphe suivant permet de mieux se rendre compte de l'overhead induie par l'implûˋmentation PL/perl et l'implûˋmentation C.
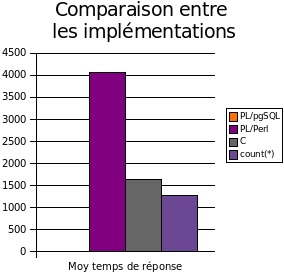
Chose trû´s intûˋressante : l'overhead pour renverser ~320000 enregistrements est de seulement 300ms, ce qui est bien entendu excellent et laisse prûˋsager de trû´s bonnes performances quant au coû£t de la mise û jour d'un index fonctionnel.
Ainsi, comme cela pouvait ûˆtre aisûˋment imaginûˋ, la version C est la plus rapide, suivie par la version PL/Perl. La version PL/pgSQL se traûÛne lamentablement derriû´re, ce qui justifie complû´tement la rûˋûˋcriture de la procûˋdure stockûˋe en C.
Notes
Cette fonction a ûˋtûˋ testûˋ sur une base en PostgreSQL 8.0, 8.2 et 8.3devel (merci û depesz).
Je regrette de ne pas avoir pu aller un peu plus loin pour le prûˋcûˋdent article, des impûˋratifs de place m'ayant obligûˋ û aller û l'essentiel sans montrer les diffûˋrents plans d'exûˋcution. Heureusement, l'article de hubert depesz lubaczewski montre tous les aspects que j'ai nûˋgligûˋ, malheureusement c'est en anglais.
Rûˋfûˋrences
De plus amples prûˋcisions sont ûˋgalement disponibles en langue anglaise sur les sites Internet suivant :
- Les index fonctionnels
- Support des jeux de caractû´res dans PostgreSQL
- Fonctions en langage C
- Writing PostgreSQL Functions in C
- What's a Varlena ?
- Le minimum syndical û connaûÛtre sur les jeux de caractû´res multi-octets
- RFC 3629, UTF-8, a transformation format of ISO 10646 ou RFC 3629
- Documentation Doxygen du code de PostgreSQL
Remerciements
Je remercie vivement les personnes suivantes :
- Alain Delorme pour sa contribution,
- hubert depesz lubaczewski pour ses retours et tests prûˋliminaires,
- Guillaume Lelarge pour ses relectures et ses conseils avisûˋs.
Article ûˋcrit par Thomas Reiss, publiûˋ sur postgresqlfr.org avec sa permission. Vous pouvez le retrouver sur son blog oû¿ il parle encore de PostgreSQL (et d'autres choses :-) ). Merci beaucoup.
| Fichier attachûˋ | Taille |
|---|---|
| comparaison_plpgsql_plperl_c_count.png | 15.26 Ko |
| ccomparaison_plperl_c_count.png | 9.86 Ko |